

Populære opslag
-
 Discover the Ultimate Scam Verification Platform for Sports Toto Sites at toto79.in
Ved denishabruni12
Discover the Ultimate Scam Verification Platform for Sports Toto Sites at toto79.in
Ved denishabruni12 -
 Купить диплом пгс.
Ved cortneymoran52
Купить диплом пгс.
Ved cortneymoran52 -
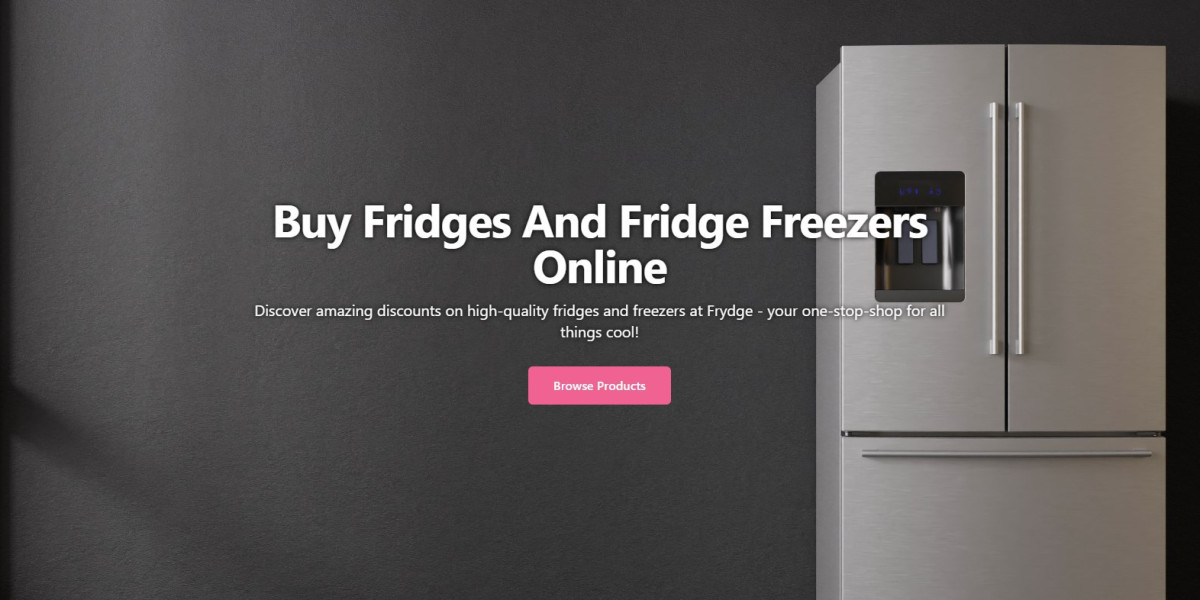 You'll Never Be Able To Figure Out This Fridge Freezers For Sale's Tricks
Ved frydge2794
You'll Never Be Able To Figure Out This Fridge Freezers For Sale's Tricks
Ved frydge2794 -
 Claim Instant Cashbacks with 1Win Bonus Code 2025
Ved Baron Sawayn
Claim Instant Cashbacks with 1Win Bonus Code 2025
Ved Baron Sawayn -
 5 Tools That Everyone In The Fireplace On Wall Industry Should Be Utilizing
5 Tools That Everyone In The Fireplace On Wall Industry Should Be Utilizing





